
Scanning paper documents and auto sorting into folders based on content
Some notes for myself on the beginnings of a big scanning project and how to organize the files that were scanned.


I'm working on a project to scan a bunch of documents and store them in cloud storage for future generations in the organization to filter through as needed. I hope I can just search in Google Drive to find the document I need and if we ever need to move away from Google Drive we can move the documents to another file storage system no problem.
What I'd like to have happen
My plan is to use an old Xerox copier that has network scanning capabilities and scan a collection of documents and have them OCR and saved to a holding place to be read, filtered and put into folders with a persons name on it and the files named for what each document is. The documents are mainly forms that were filled out with handwriting and the other documents are things collected as the person was a member of the organization. The forms go back to most likely the 1950, heck even earlier and most likely are about 500 or so folders, one for each person.
What I have
Scanner
I'm working with an older Xerox copier that has network capabilities that can do the scanning and saving to SMB share or USB thumb drive. I'm not sure I can rely on the OCR of this scanner since it's capabilities are locked in to the area in which it was created. Doing a second pass of OCR scanning may be best with more modern hardware and software.
Computers
Raspberry Pi 4 - I have a raspberry pi with an external harddrive on it to do some data collection and then connected to the internet push the data to Google Drive as its final resting place.
Macbook Pro M2 - If it would make it easier to do any on device AI for reading the documents this may be a good way to do it.
Storage
We're looking to store this content on Google Drive so we can leverage the search capabilities of Google drive to find content easy and search the OCR data in the future if we need to find a specific collection of content based on keywords.
Lots of Documents
Like I wrote in the intro, I have about 500 or so hanging files in a cabinet of records from people in the organization and each folder has 1-30 pages of documents that need to be unstapled, scanned and organized. These documents are applications, application fees, and other documents outlining various statuses a person as been through. These documents were used in the past as a way to keep track of such things but have been replaced with online tools to do the same thing. For record keeping sake we would like to keep these documents scanned as PDFs in case we ever need to reference them since most of them havent made it into the online tool that we use.
Organization
Honestly I'm not really looking for a tool that has its own database and has its own way of storing things. I'm mainly looking for a file processor that can take a file from the printer (sitting in an SMB share) and read the OCR data in it then using a few phrases it finds can help rename the file and store it in a folder with the persons name in it. I'm thinking there may be 10 types of documents to scan and just need the files named and the folders they live in created.
Solutions I have used in the past
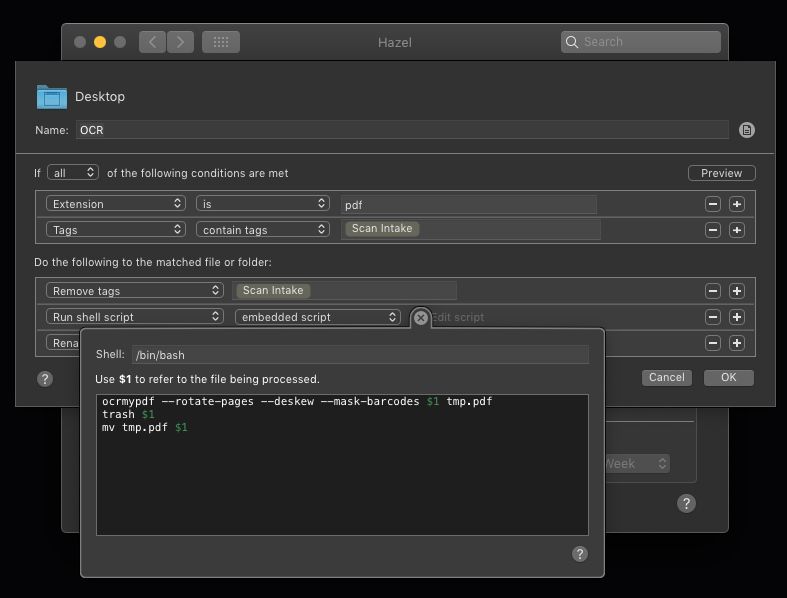
Hazel
I've used Noodlesoft's Hazel before on the Mac to process files based on lots of criteria. This solution is most likely what I'll start using but it is limited in some respects. They have a lively online forum with many people using this tool to rename and organize documents just like me.
Articles I've found using Hazel or could be used with Hazel

Extending my research
Paperless-ngx
I started my journey with looking at Paperless-ngx as a solution to help with reading the documents and setting up routes for what filename a scanned file should have based on the contents of the file. It then store the files in the file system so you can do what you need to with them. It has a web interface
Papermerge DMS
Another solution is Papermerge DMS which looks interesting and a few folks have mentioned on Reddit as a solution to this problem. It's a document management system runs it's own web server. I've been researching how it manages the files it scans and what it can do with the files. Personally I think this solution isnt the best fit for me since it most likely relies on the software and the PDFs arent changed in any way. It just collects meta data and stores it. I'll need to look further into this later.
Teedy
I have seen this one mentioned a few times - Teedy which looks like another interesting way to do this. Seems like it is more of a database than a processor.
More to go
I'm going to start scanning some documents, find the commonalities in those files in that data set and work out how I want to organize that data. Then try a few OCR solutions and how that data is stored in a PDF/A file format and how Hazel can be used to do some of the organization. I'd love to find a way to have a raspberry pi setup near the copier that at a press of the button on the Xerox copier send the scanned document to a folder that the raspberry pi is watching, OCR and then organize the file and push it to Google. One can dream, lets start small and work out way toward what I want.
What's next?
I'll add to this document so I have something for me to reference and something for you to comment on below if you have approached this problem differently than I have.



